The Intel® Extension for PyTorch* for GPU extends PyTorch with up-to-date features and optimizations for an extra performance boost on Intel Graphics cards.
This article delivers a quick introduction to the Extension, including how to use it to jumpstart your training and inference workloads.
Support for GPUs, AI Performance Optimizations, and More
The latest Intel® Extension for PyTorch* release introduces XPU solution optimizations. XPU is a device abstraction for Intel heterogeneous computation architectures, that can be mapped to CPU, GPU, FPGA, or other accelerators. The optimizations include:
- Support for Intel GPUs. The runtime will choose the actual device when executing AI workloads and Intel GPU will be selected as the default device. The latest release supports all the Intel GPU platforms - Intel® Data Center GPU Flex Series, Intel® Data Center GPU Max Series and Intel® Arc™ A-Series Graphics.
- Enables the most up-to-date Intel® software and hardware AI optimizations, including up-streaming several optimizations into the stock version of the framework for out-of-the-box performance gains.
- Uses the Intel® oneAPI DPC++ Compiler which supports the latest SYCL* standard and also a number of extensions to the SYCL* standard, which can be found in the sycl/doc/extensions directory.
- Integrates Intel® oneAPI Deep Neural Network Library (oneDNN) and Intel® oneAPI Math Kernel Library (oneMKL) and provides kernels based on that. oneDNN library is used for computation intensive operations and oneMKL library is used for fundamental mathematical operations.
The Structure
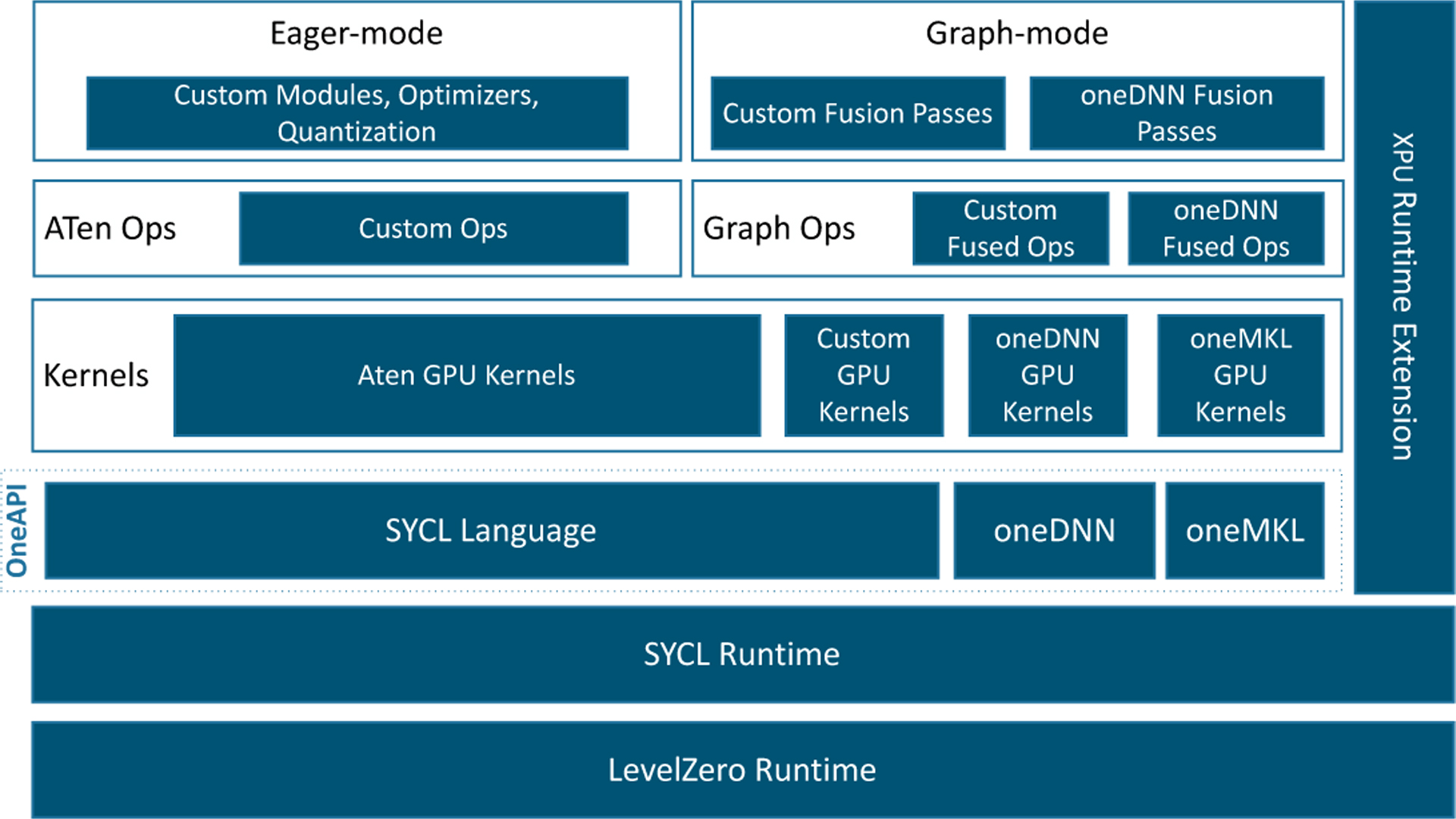
In the above figure, PyTorch components are represented with white boxes and Intel extensions are represented with blue boxes.
The additional performance of the extension comes from optimizations for both eager mode and graph mode. In eager mode, the PyTorch frontend is expanded with custom Python* modules (such as fusion modules), optimal optimizers, and INT8 quantization API. Additional performance boosting is available by converting the eager-mode model into graph mode via extended graph fusion passes. For the device backend, optimized operators and kernels are implemented and registered through PyTorch dispatching mechanism.
Features
Intel Extension for PyTorch includes several features that optimize AI performance on GPUs.
- Auto Mixed Precision (AMP): The support of AMP with BFloat16 and Float16 optimization of GPU operators has been enabled in the Intel extension. torch.xpu.amp offers convenience for auto data type conversion at runtime. Inference workloads using torch.xpu.amp supports torch.bfloat16 and torch.float16. Training workloads using torch.xpu.amp supports torch.bfloat16. torch.bfloat16 is the default lower precision floating point data type when torch.xpu.amp is enabled. We suggest using AMP for accelerating convolutional and matmul-based neural networks. For more additional information, check Auto Mixed Precision.
- Channels Last: Compared with the default NCHW (batch N, channels C, height H, width W) memory format, using channels_last (NHWC) memory format can further accelerate convolutional neural networks. In Intel Extension for PyTorch, channels_last (NHWC) memory format has been enabled for most key GPU operators. For more detailed information, check Channels Last.
- DPC++ Extension: Based on the PyTorch C++ extension mechanism, the Intel extension lets you create PyTorch operators with custom DPC++ kernels to run on the selected device. DPC++ Extension describes how to write customized DPC++ kernels with a practical example and build it with setuptools and CMake.
- Distributed Training and Inference: Intel® GPUs support distributed training with either PyTorch native distributed training module, Distributed Data Parallel (DDP), with Intel® oneAPI Collective Communications Library (oneCCL) support via Intel® oneCCL Bindings for PyTorch (formerly known as torch_ccl) or use Horovod with Intel® oneAPI Collective Communications Library (oneCCL) support (Experimental). Stock DeepSpeed is also now supported on Intel GPU with all essential DS features like automatic tensor parallelism for inference, ZeRO 1/2/3 and 3D parallelism etc for training.
- Fully Sharded Data Parallel (FSDP): Unlike DDP, FSDP (data parallel training) shards model parameters, optimizer states and gradients across DDP ranks to reduce GPU memory footprint. For more additional information, check FSDP.
- Inductor: Graph compilation capabilities can be harnessed for optimal performance via the flagship torch.compile API through the default “inductor” backend (TorchInductor).
- Large Language Models (LLM) Optimizations: Intel Extension offers highly efficient LLM specific optimizations such as GEMM kernel to speed up Linear layer, customized operators (Rotary Position Embedding RoPE, RMSNorm) to reduce the memory footprint, low-precision solutions such as smoothQuant, weight-only-quantization, Operator fusion, Segment KV Cache and Distributed Inference to get best performance and accuracy. This can be further optimized by using deepspeed (model sharding) for distributed training and inference. These can be applied with single frontend API function, ipex.optimize_transformers(). For more detailed information, check LLM Optimizations Overview.
Getting Started with Intel Extension for PyTorch for GPU
Installation
The extension can be installed with the command below after setting up the OS specific drivers and Intel® oneAPI Base Toolkit:
python -m pip install torch==2.1.0a0 torchvision==0.16.0a0 torchaudio==2.1.0a0 intel-extension-for-pytorch==2.1.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
Find complete details with other releases >
Training
There are only minor code changes required to use the extension on training.
- Import Intel Extension for PyTorch package. - import intel_extension_for_pytorch as ipex
- ipex.optimize function applies optimizations against the model object, as well as an optimizer object.
# For Float32
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.float32)
# For BFloat16
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16) - Use Auto Mixed Precision with BFloat16 data type.
# For BFloat16
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16): - Convert both tensors and models to XPU.
model = model.to("xpu")
data = data.to("xpu")
target = target.to("xpu")
Please check out examples for Float32 and BFloat16 training.
Inference
Channels last is a memory layout format that runs well on Intel® architecture. We advise using this memory-layout format for computer-vision workloads by using to(memory_format=torch.channels_last) function against the model object and input data. The code changes required to use Intel Extension for PyTorch on inference are:
- Import Intel Extension for PyTorch package. - import intel_extension_for_pytorch as ipex
- torch.channels_last should be applied to both the model object and data.
model = model.to(memory_format=torch.channels_last)
data = data.to(memory_format=torch.channels_last) - ipex.optimize function applies optimizations against the model object.
# For Float32
model = ipex.optimize(model, dtype=torch.float32)
# For BFloat16
model = ipex.optimize(model, dtype=torch.bfloat16) - Use Auto Mixed Precision with BFloat16 data type.
with torch.xpu.amp.autocast(enabled=True, dtype=torch.bfloat16, cache_enabled=False): - Convert both tensors and models to XPU.
model = model.to("xpu")
data = data.to("xpu")
Please check out examples for Float32 and BFloat16 inference.
Like Float32, the optimize function also works for Float16 data type. The only difference is setting dtype parameter to torch.float16. We recommend using Auto Mixed Precision (AMP) with Float16 data type. Also, please visit this link for Float16 inference examples.
What's Next?
Intel Extension for PyTorch for GPU is released as an open source project on GitHub xpu-main branch. For further details, please read the release notes. We also encourage you to check out and incorporate Intel’s other AI/ML Framework optimizations and end-to-end portfolio of tools into your AI workflow and, learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio.
Useful Resources
- Intel AI Developer Tools and resources
- oneAPI unified programming model
- Intel® Extension for PyTorch* for GPU - Documentation
Get the Software
Download the Intel Extension for PyTorch standalone or as part of the AI Tools Selector.